Web Sracping Presentation
| Introduction to Web Scraping | ||
|---|---|---|
| Web scraping is the process of extracting data from websites. It involves using automated tools or scripts to access and retrieve specific information from web pages. Web scraping can be used for various purposes, such as data analysis, market research, or competitor analysis. | ||
| 1 | ||
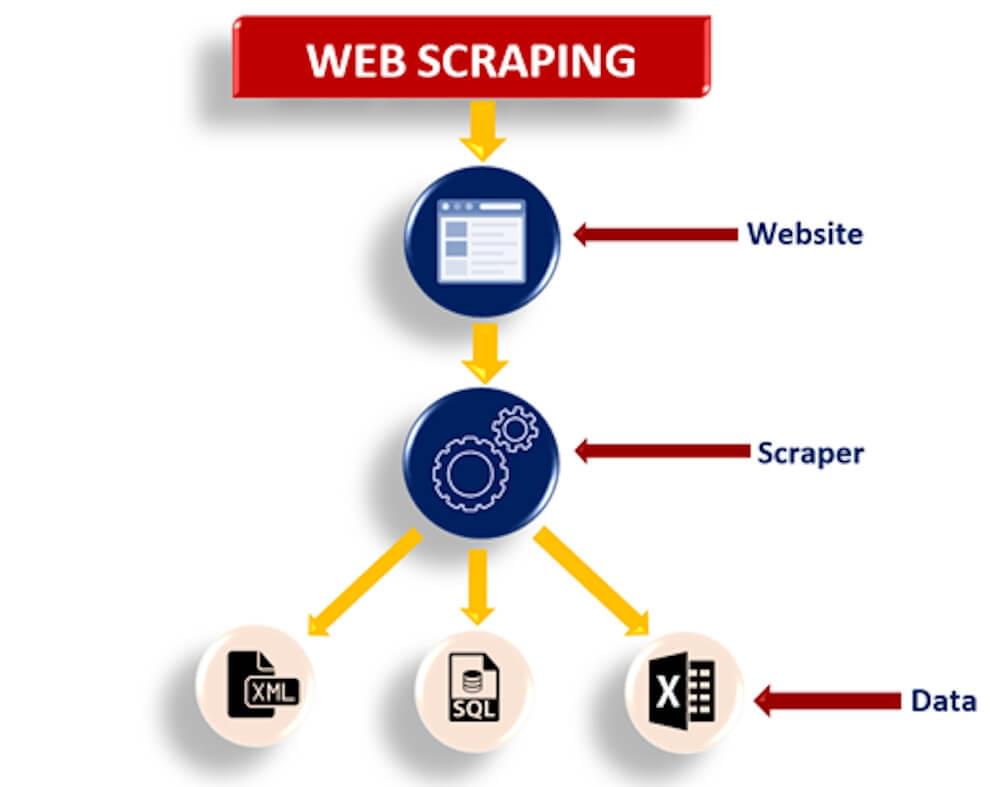
| Benefits of Web Scraping | ||
|---|---|---|
| Web scraping allows for efficient data extraction, saving time and effort compared to manual data collection. It enables access to large amounts of data that may not be readily available or accessible in a structured format. Web scraping provides the ability to monitor and track changes on websites, such as pricing or product updates. | ||
| 2 | ||

| Techniques for Web Scraping | ||
|---|---|---|
| Basic HTML parsing: Extracting data by directly parsing the HTML structure of a webpage. Using APIs: Accessing data through Application Programming Interfaces (APIs) provided by websites. Automated browser tools: Utilizing tools like Selenium WebDriver to interact with websites and extract data. | ||
| 3 | ||

| Considerations for Web Scraping | ||
|---|---|---|
| Respect website terms of service: Ensure compliance with website rules and policies when scraping data. Be mindful of legal restrictions: Understand the legal implications of web scraping and the data obtained. Use proper scraping etiquette: Avoid putting excessive strain on servers and be considerate of website resources. | ||
| 4 | ||

| Tools for Web Scraping | ||
|---|---|---|
| Beautiful Soup: A Python library for parsing HTML and XML documents, making it easy to extract data. Scrapy: A powerful and flexible Python framework for web scraping, providing tools for data extraction and web crawling. Puppeteer: A Node.js library that provides a high-level API to control headless Chrome or Chromium browsers. | ||
| 5 | ||

| Challenges of Web Scraping | ||
|---|---|---|
| Website structure changes: Websites frequently update their structure, requiring adjustments to scraping scripts. Captchas and anti-scraping measures: Some websites employ measures to prevent or limit scraping activities. Dynamic content: Pages that load content dynamically through JavaScript can pose challenges for scraping. | ||
| 6 | ||

| Best Practices for Web Scraping | ||
|---|---|---|
| Respect robots.txt: Check a website's robots.txt file to understand scraping permissions and limitations. Use caching and delays: Implement caching mechanisms and introduce delays to avoid excessive requests. Regularly monitor and update scraping scripts: Keep an eye on website changes and adjust scraping scripts accordingly. | ||
| 7 | ||

| Ethical Considerations | ||
|---|---|---|
| Obtain data ethically: Ensure that the data being scraped is publicly available and does not violate any legal or ethical boundaries. Protect personal information: Be cautious when scraping websites that handle sensitive user data. Use data responsibly: Respect privacy, copyright, and intellectual property rights when using scraped data. | ||
| 8 | ||

| Use Cases for Web Scraping | ||
|---|---|---|
| Price monitoring and comparison: Scraping e-commerce websites to track and analyze price fluctuations. Market research and competitor analysis: Extracting data from competitor websites to gain insights and make informed business decisions. Content aggregation: Collecting information from multiple sources to create comprehensive reports or databases. | ||
| 9 | ||

| Conclusion | ||
|---|---|---|
| Web scraping is a valuable technique for extracting data from websites. It offers numerous benefits, but also presents challenges and ethical considerations. By following best practices and being mindful of legal and ethical boundaries, web scraping can be a powerful tool for data extraction and analysis. | ||
| 10 | ||
| References (download PPTX file for details) | ||
|---|---|---|
| "Web Scraping" by Wikipedia: https:// en.wiki... "A Beginner's Guide to Web Scraping with Pyth... "Web Scraping with Python: A Comprehensive Gu... |  | |
| 11 | ||