Transformer Algorithm Presentation
| Introduction to Transformer Algorithm | ||
|---|---|---|
| The Transformer Algorithm is a popular machine learning model architecture. It was introduced by Vaswani et al. in 2017 and has since become widely adopted. The Transformer Algorithm is based on the concept of self-attention. | ||
| 1 | ||
| Key Components of the Transformer Algorithm | ||
|---|---|---|
| The Transformer Algorithm consists of an encoder and a decoder. The encoder processes the input sequence and generates a set of hidden representations. The decoder takes these hidden representations and generates the output sequence. | ||
| 2 | ||
| Self-Attention Mechanism | ||
|---|---|---|
| Self-attention allows the Transformer Algorithm to weigh the importance of different input elements when generating output. It captures dependencies between words in a sentence, regardless of their position. Self-attention enables the model to focus on relevant parts of the input sequence. | ||
| 3 | ||
| Multi-Head Attention | ||
|---|---|---|
| Multi-head attention is a variant of self-attention used in the Transformer Algorithm. It consists of multiple sets of attention weights, called attention heads. Each attention head attends to different parts of the input sequence, providing more diverse and comprehensive information. | ||
| 4 | ||

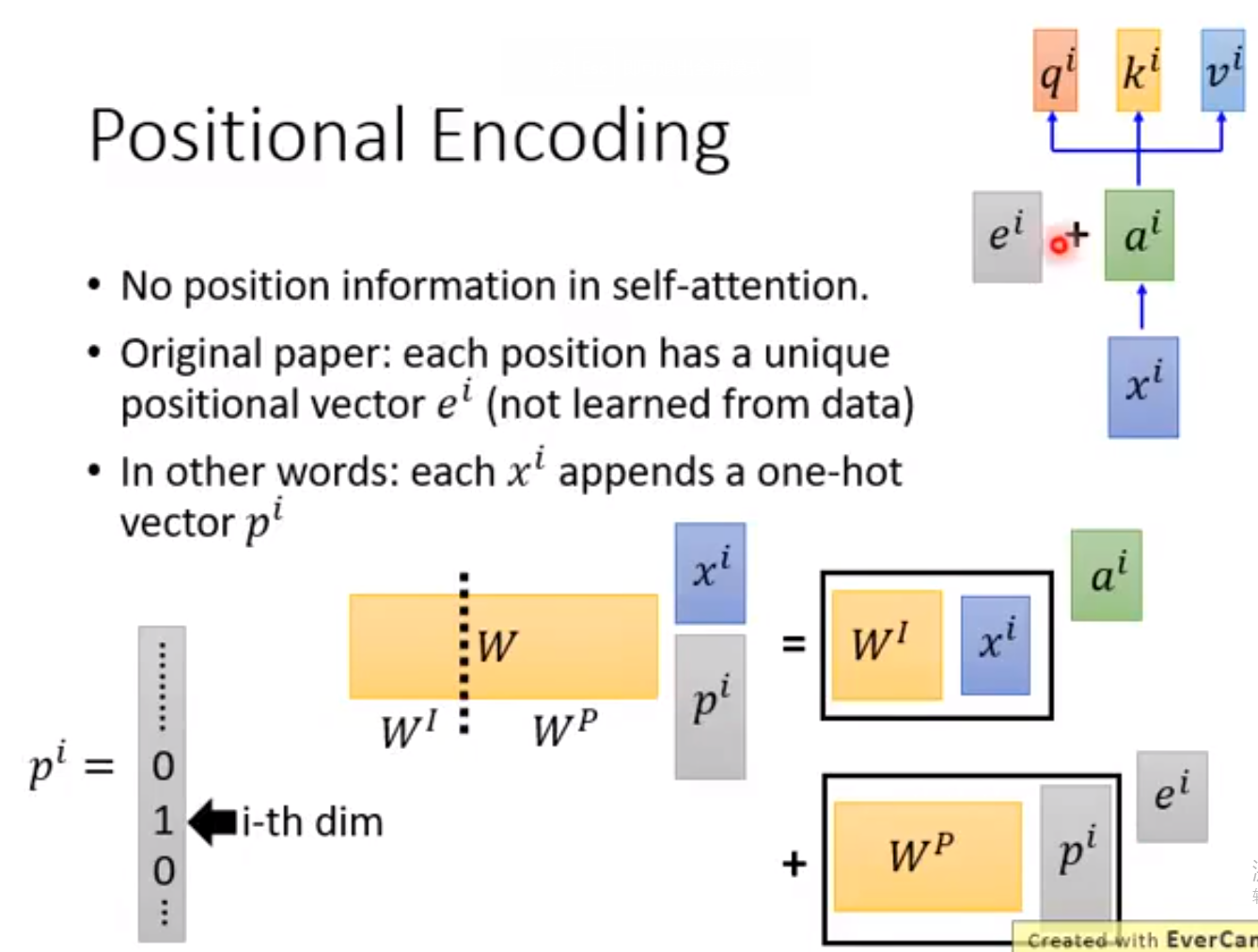
| Positional Encoding | ||
|---|---|---|
| Positional encoding is used to capture the order or position of words in a sentence. It is added to the input embeddings to provide the model with positional information. Positional encoding helps the Transformer Algorithm handle sequences of variable length. | ||
| 5 | ||
| Feed-Forward Neural Networks | ||
|---|---|---|
| The Transformer Algorithm employs feed-forward neural networks as part of its encoder and decoder. These networks consist of multiple layers of fully connected linear and activation functions. Feed-forward networks help capture complex patterns and relationships in the data. | ||
| 6 | ||

| Training and Optimization | ||
|---|---|---|
| The Transformer Algorithm is typically trained using the backpropagation algorithm and gradient descent. It uses a variant of gradient descent called Adam optimizer to update the model parameters. Training often involves large-scale datasets and can be computationally intensive. | ||
| 7 | ||
| Applications of Transformer Algorithm | ||
|---|---|---|
| The Transformer Algorithm has been successfully applied to various natural language processing tasks, such as machine translation and text summarization. It has achieved state-of-the-art performance in many language-related benchmarks. The Transformer Algorithm has also been adapted for computer vision tasks, such as image captioning. | ||
| 8 | ||
| Advantages of Transformer Algorithm | ||
|---|---|---|
| The Transformer Algorithm can capture long-range dependencies in sequences more effectively than traditional recurrent neural networks. It allows for parallel computation, making it more efficient to train and deploy. The self-attention mechanism enables the model to handle inputs of variable lengths. | ||
| 9 | ||
| Conclusion | ||
|---|---|---|
| The Transformer Algorithm has revolutionized the field of natural language processing. Its ability to capture dependencies and generate high-quality outputs has made it a go-to choice for many language-related tasks. Further research and improvements are being made to enhance the Transformer Algorithm's performance and expand its applications. | ||
| 10 | ||